ML Platform
Vianai Systems · Product Design
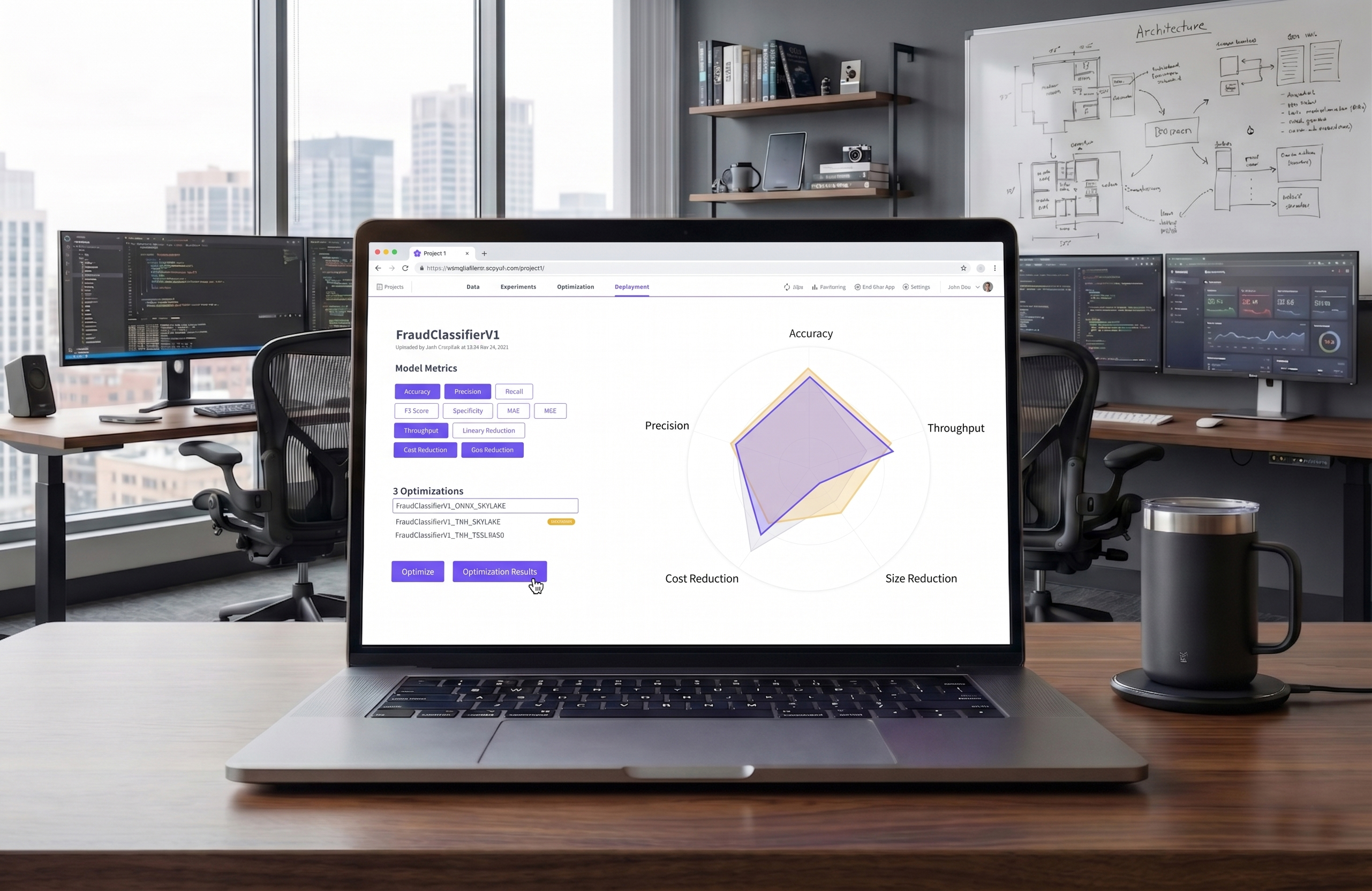
End-to-end machine learning platform that takes models from raw data to production deployment — designed for the teams who build AI.
The Challenge
ML projects rarely survive the journey to production. Fragmented tooling, broken handoffs, and infrastructure complexity mean that even proven models frequently stall out in the proof-of-concept stage.
While partnering with enterprise clients like JPMC, Schlumberger, and ZipRecruiter, we saw a consistent theme: ML tooling was fragmented by design. We set out to build a unified platform covering the full ML workflow—from raw data ingestion to optimized model deployment.
Strategic Framework: We mapped the platform to how ML teams actually work across four distinct phases: Explore, Build, Use, and Explain. This structure anchored our navigation, permission models, and product roadmap.
The Impact
- Tool Consolidation: Reduced the core operational footprint for enterprise AI teams from 5+ fragmented utilities down to 1 unified environment.
- Product Evolution: Designed the closed-loop architecture that later spun out into VianOps, Vianai's standalone model health and monitoring product.
- Enterprise Validation: Successfully addressed divergent infrastructure gaps for three major launch partners (Finance, Energy, and Talent Acquisition domains).
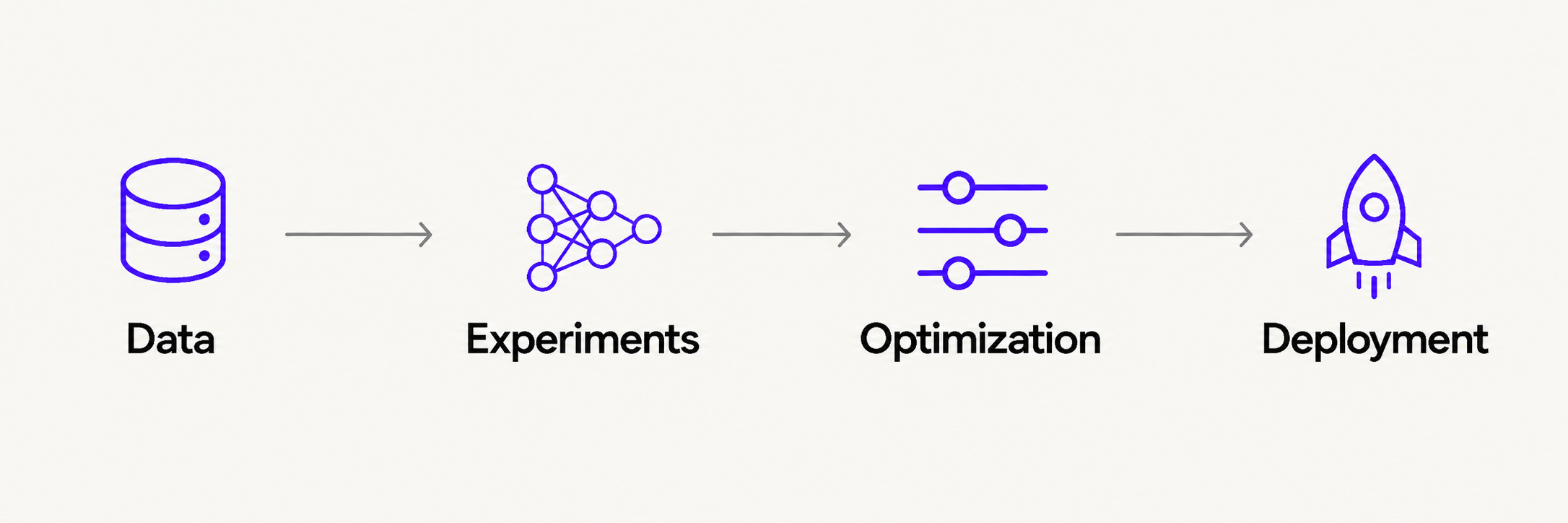
Platform Architecture
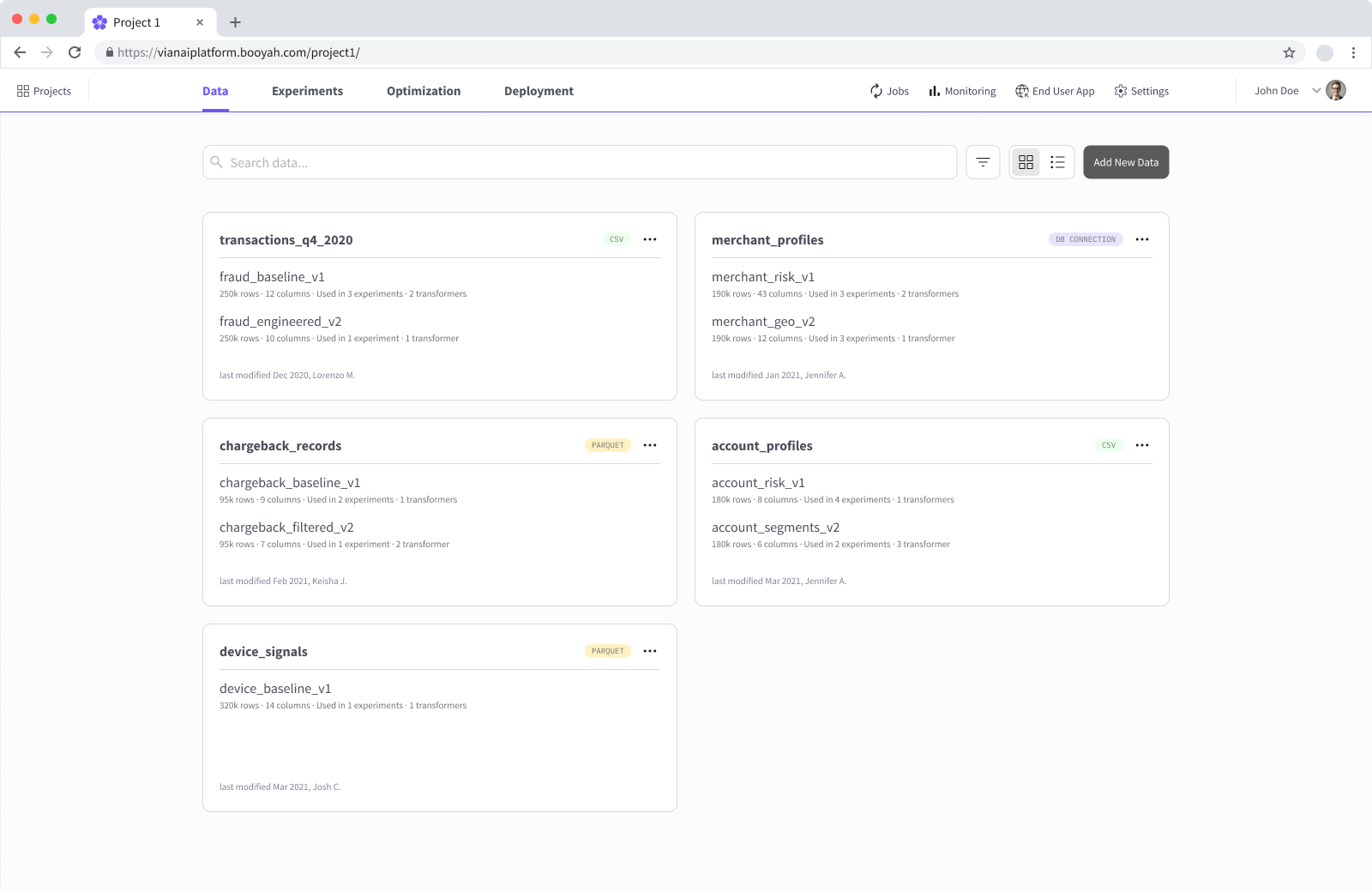
Data
Ingest, map, and transform datasets into versioned feature sets ready for training.
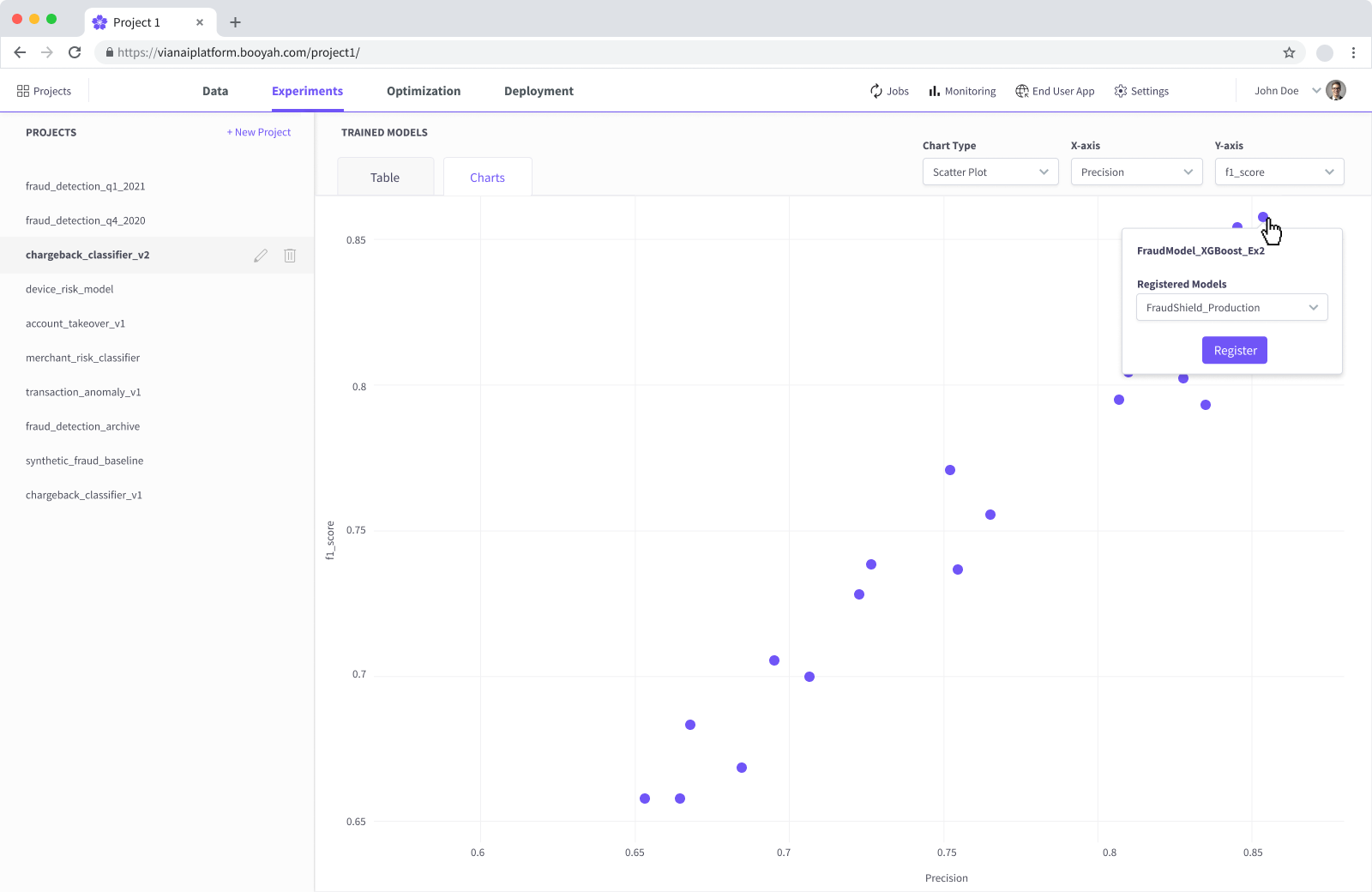
Experiments
Configure training runs, monitor active jobs, and compare model performance across experiments.
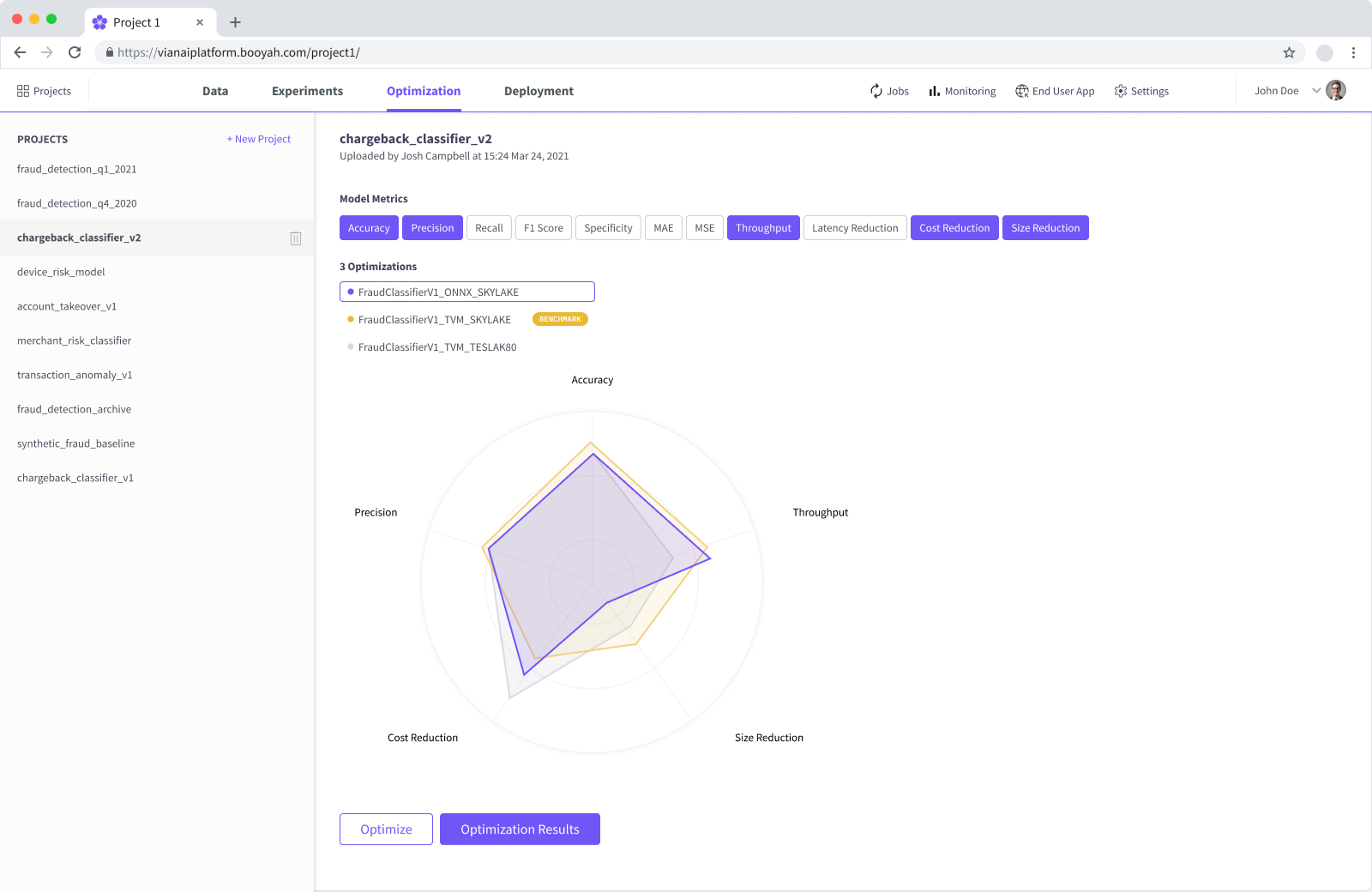
Optimization
Surface hardware and runtime trade-offs to find the best model for production constraints.
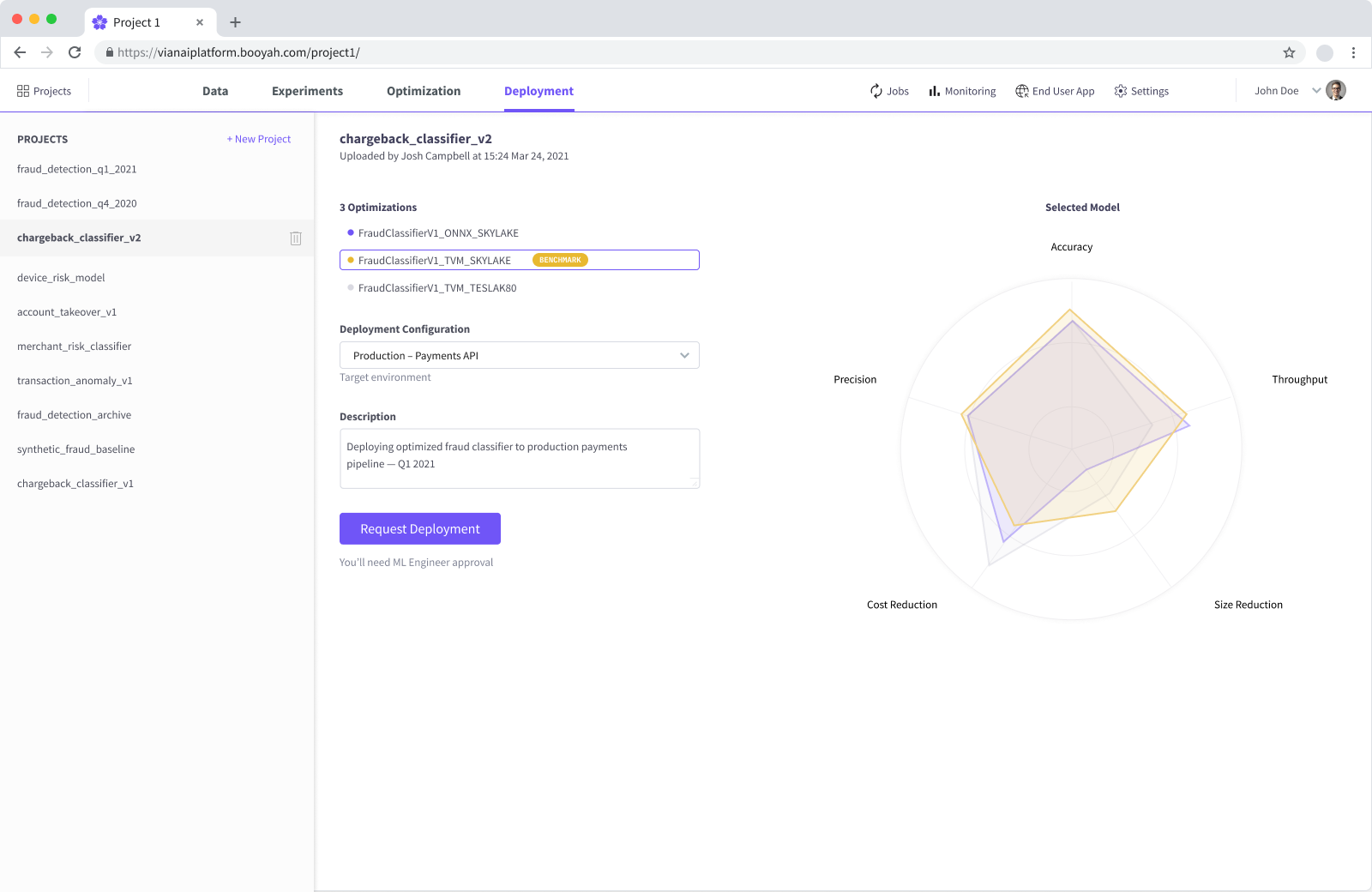
Deployment
Request, review, and approve model deployments with role-appropriate controls.
Core Design Decisions
1. Abstracting Infrastructure Without Hiding Trade-Offs
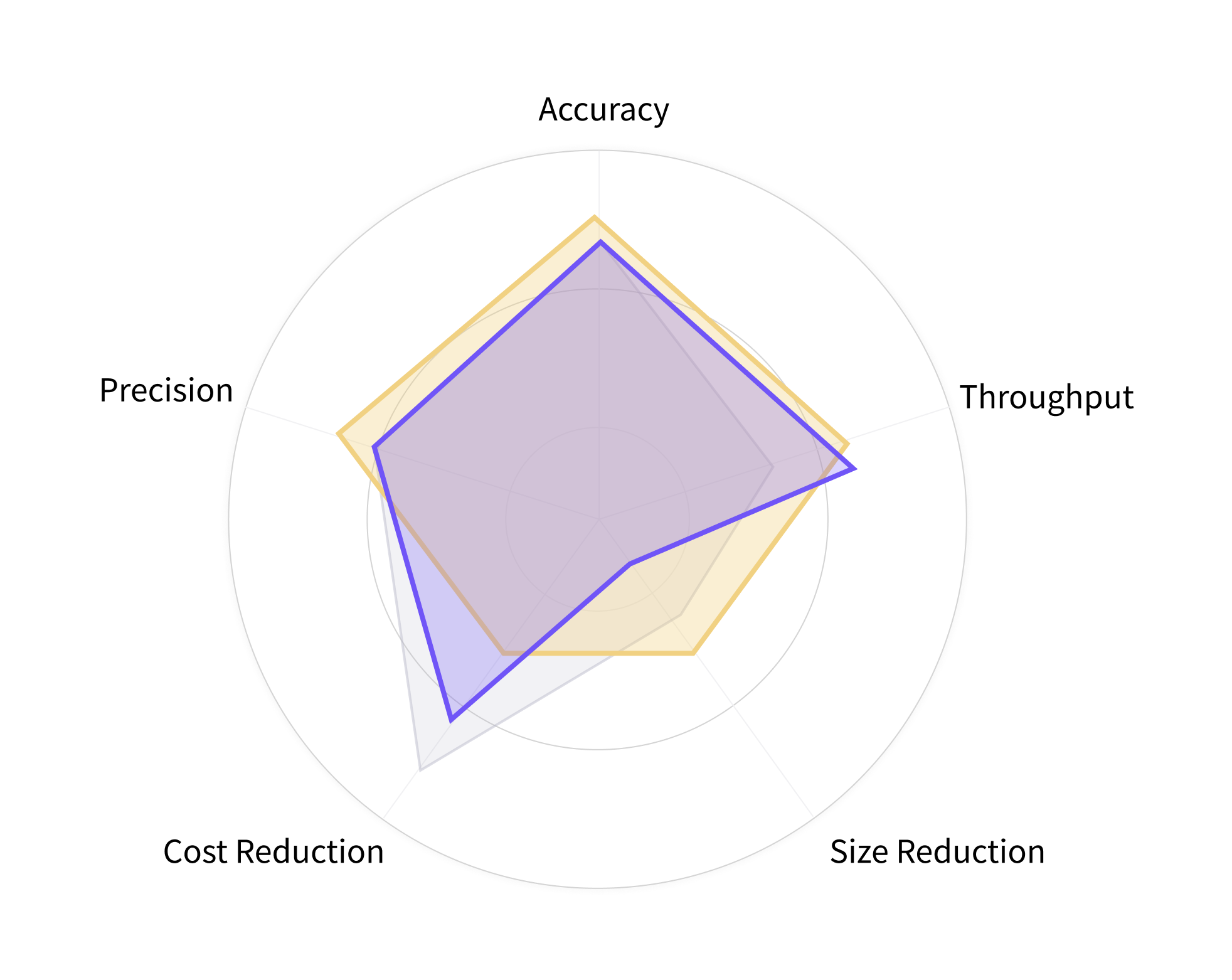
Data scientists need to see operational outcomes, not underlying cloud hardware complexity. I designed a radar chart visualization that makes cost, latency, and accuracy trade-offs immediately legible. Hardware targets remain admin-configured, allowing data scientists to optimize for production constraints without needing a background in infrastructure engineering.
2. Role-Based Controls as Organizational Workflow
Rather than utilizing rigid, binary permission gates, the platform encodes collaborative workflow. The same deployment action renders differently based on whether the user is a Data Scientist (request), an ML Engineer (approve), or an IT Admin (govern). Deployment becomes a collaborative handoff rather than a friction point.

3. Designing for the Full Team, Not a Single Persona
To eliminate out-of-band communication (like coordinating handoffs over Slack), every screen maintains shared context across roles. By utilizing author attribution, shared job queues, and a unified model registry, the entire cross-functional team stays aligned within a single environment rather than context-switching across Jupyter, MLflow, and cloud consoles.
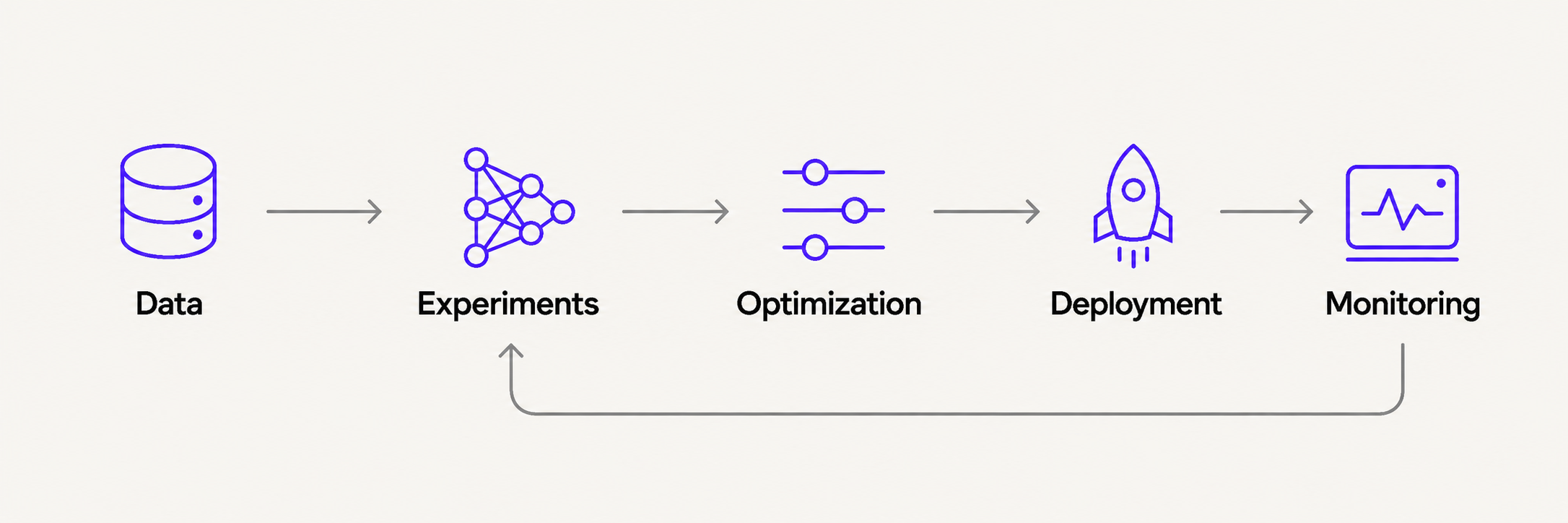
4. Closing the Loop
Most MLOps tools treat deployment as the finish line; we treated it as a checkpoint. When a model drifts or degrades in production, the monitoring layer automatically routes it backward to the appropriate stage—minor degradation goes to optimization, while significant drift routes back to experiments for retraining.
The Outcome
The platform launched to strategic enterprise partners in Q4 2021. Feedback consistently validated the reduction in context switching, proving that data scientists could successfully move an investment from experiment to live serving without requiring a dedicated MLOps engineer for every single deployment.